

In our last blog, we showed how a multi-tier browser agents architecture helped us beat state-of-the-art models on the Online‑Mind2Web (Online‑M2W) benchmark. To make the work relevant for enterprises, the agents need to be durable, tolerant and resilient. This blog is focused on agent‑specific decisions: how the planner reasoned, which tools were invoked and why, and how the browser was perceived.
Here we describe the agentic environment that made those results possible and we explain why this environment is now central to how we evaluate agents, reduce variance in online benchmarks, and generate labelled trajectory data that can be reused to train smaller, cheaper computer‑use agents. Using durable agents to generate training data for computer-use workloads, has widespread implications when building other custom fine-tuned models.
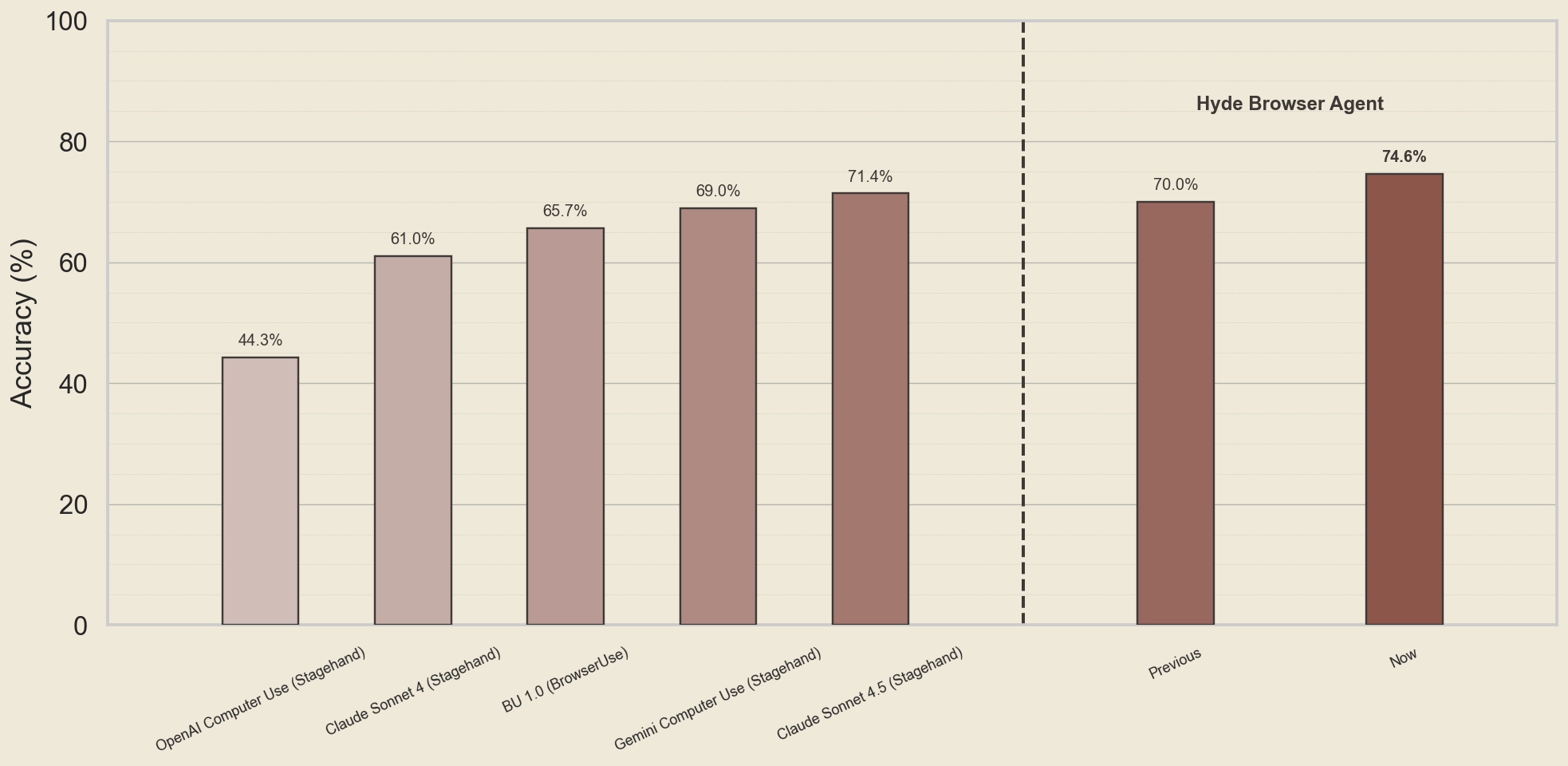
Why durability matters for AI agents
Agent benchmarks are not static question‑answer tasks. They are long‑horizon, multi‑step interactions with systems that are:
- Non‑deterministic
- Externally stateful (browsers, websites, APIs)
- Prone to transient failures
A single browser timeout or tool hiccup can invalidate an otherwise correct trajectory. Without durability, these failures don’t just reduce accuracy - they erase signal. Durability turns agent evaluation from best‑effort execution efforts into repeatable task automation machines.
The core analogy: agents as probabilistic state machines
We can treat an agent as a probabilistic finite state machine (PFSM), and the platform that runs it as a state‑machine orchestration engine. Formally, a probabilistic finite state machine can be defined as:
M = (S, Σ, δ, s₀, F)
Where:
- S is the set of possible states
- Σ is the input alphabet (observations)
- δ : S × Σ → Dist(S) is a transition function that returns a probability distribution over next states
- s₀ is the initial state
- F is the set of terminal (halting) states
Agents feel open‑ended because transitions are probabilistic, state extends beyond model memory into the external world, and failures are only visible across sequences of transitions**.** If an agent is a probabilistic state machine, then a platform executing it must:
- Persist state durably across crashes and restarts
- Retry transitions selectively, only when failures are environmental
- Record every transition so the full trajectory is inspectable
- Define terminal states explicitly rather than relying on timeouts
Naïve agent loops - while not done: call LLM - implicitly assume that transitions are reliable and disposable. That assumption fails immediately on the open web. Durability is what allows probabilistic state machines to run in hostile, real‑world environments.
From analogy to architecture
Broad system architecture (agent execution + durability)

What a single durable run looks like (Temporal view)
Each horizontal interaction corresponds to a state transition. If the browser or tool fails, Temporal retries the transition without losing prior context.
.svg)
- Automatic retries: We retry only on environment failures (timeouts, browser crashes). Completed but incorrect trajectories are never retried. This recovered a significant fraction of near‑successful runs.
- Longer, more realistic runs: Durability allowed us to increase step budgets safely. Several tasks that previously failed simply required additional exploration and backtracking.
- Self‑correcting loops via a monitoring agent: A monitoring agent inspects the trajectory in flight and detects repeated unproductive actions, stalled progress, and an exhausted search space. When triggered, it forces replanning or terminates the run cleanly.
Evaluating trajectories, not answers: Multi-agent evaluation and trajectory labelling
.svg)
Judges evaluate the entire trajectory (task, actions, observations, stop gate), not just the final answer. A run is successful if at least 2 out of 3 judges agree. Evaluating agents requires an evaluation of the state evolution, not final outcome alone.
Three‑judge evaluation
Each trajectory is evaluated by three independent LLM judges that inspect the full trajectory.
A trajectory consists of:
- The task specification
- The full sequence of observations and actions
- A stop gate, triggered when the monitoring agent believes the primary agent has exhausted all options or is confident in completion
Only after crossing the stop gate is a trajectory submitted for evaluation.
Success criteria
- Successful run: ≥ 2/3 judges label the trajectory as successful
- Successful task: ≥ 1/5 runs for that task is successful
This definition reduces variance from model nondeterminism and live‑web instability.
From evaluation to synthetic data
A key outcome of durable platforms with built‑in evaluation loops is that they naturally generate high‑fidelity synthetic data. Every successful trajectory contains grounded observations, explicit actions, recovery behaviour and clear terminal conditions. These ingredients are vital to building out supervised fine‑tuning (SFT) of smaller computer‑use agents.
Instead of collecting human demonstrations, we, run agents at scale, filter trajectories with strong evaluators, and retain only high‑confidence successes. This mirrors recent research directions that show scalable trajectory generation can unlock strong performance from smaller models [1].
Going forward, we intent to use this corpus to replay trajectories to compare different models under identical conditions (and hence evaluate the right strategy for an agent while executing a task), and to fine‑tune smaller models on successful trajectories thereby reducing inference and training cost. Evaluation data for long-running durable agents, becomes the training data for repeatable day-to-day tasks.
Agents are not single calls- they are evolving systems. Thinking of them as probabilistic state machines gave us a precise way to reason about execution, durability, and evaluation. By building durability and evaluation into the core runtime, we didn’t just improve benchmark scores - we built a pipeline that continuously generates reusable, high‑quality trajectory data, paving the foundation of becoming practical model training infrastructure.
References
- Awadallah et al. Fara-7B: An Efficient Agentic Model for Computer Use